How Babble's face tracking works

Previously, I wrote an article describing how our eye tracking works. While we have given fully-fledged presentations in person and virtually on how our face tracking works, it's only dawning on me that we have never written a blog post on this. Heck!
At a high level, our face model is a heavily modified EfficentNetv2. Unlike our eye model, which requires a per-user calibration, our face model is a strong generalist model that will work out of the box.
Motivations
Before Babble, you had a handful of face tracking solutions for use in Social VR:
Vive
I'm no stranger to the Vive Facial Tracker:
Vive Facial Tracker


Released in March 2021, the VFT is considered to be the first accessory of its kind. And for the most part, most of its expressions are tracked pretty well without any kind of calibration. Of course, it has a handful of shortcomings:
- Picky camera placement. It was designed with Vive products in mind.
- Poor tongue shape tracking (tongue twist, flat, skinny).
- Black box without any feedback to the user.
Vive also had a number of other products:
Vive Focus 3 Facial Tracker


Vive "Squidward" Full Face Tracker

All of the above accessories leverage the SRanipal runtime and track SRanipal shapes.
However, all of these existed in a further locked down ecosystem. At one point, Vive updated their software to work only if the accessory was plugged into a Vive headset.
Meta
Quest Pro

Tracks FACS expressions.
Pico
Pro 4 Business/Enterprise

Tracks arkit expressions.
We wanted to surpass all of these in terms of cost and quality. We also wanted to challenge the Quest Pro, Pico, etc. and other headsets in terms of fidelity. Additionally, we also wanted to emphasize user privacy, and data privacy.
History
In order to train an AI model, you need a lot of data. This shouldn't come as a surprise to anyone in 2026 who hasn't been living under a rock. Where do you get data? The internet, of course!
However, to train a face-tracking model you need a lot of face data. This was the first roadblock we had to surmount, some datasets exist:
However, none of these contain the right information we needed to train a face tracking model. What we really need are blendshapes, a normalized 0-1 metric representing a facial expression.
We needed a image dataset with:
- Lower faces (the above datasets contained the full face)
- Close up, high FOV images (4 inches from the lower face @ 160 degrees)
- Large variety of faces represented (skin tone, lighting, face shape, facial hair, etc.)
And a lot of images. Millions of them, with blendshapes to match!
Datasets
The Original Dataset
The original dataset utilized SummerSigh's iPhone and a Vive Facial Tracker.
This had a handful of issues:
- Limited data generation
- Images not representative of VR headset camera placement
End result? Mediocre

Synthetic Dataset v1
Synthetic Dataset v1 took a more intelligent approach. We used free 3D assets to generate diverse facial images. This produced the first general models that could run on other user’s computers. Below is an early render:

Over the course of 2 years we improved:
- Face shapes
- Skin textures
- Camera positions
- Lighting
- Number of face (meshes) used
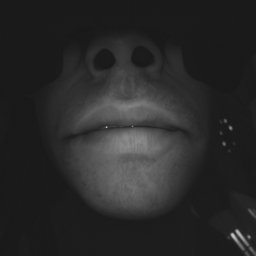

We used this approach until Babble App v2.0.5.
Up until this point we have only talked about synthetic data. Real data is incredibly useful. It dramatically tracking quality increase, and is great for edge cases. Facial hair? Weird Camera images? Covered.
At this point we began user data submission to our models! This came with its own challenges:
- Still requires good synthetic data
- Prone to user error
- Poor timing, incorrect expressions, labor intensive
- Too many identical examples
- Model overfits
Synthetic Dataset v2
Real data submissions exposed shortcomings with synthetic data. Newer data is significantly more diverse with facial hair, face shape, skin tones, lighting, image positions. We had more examples of edge cases to play with. Here is an example of a newer render:

Importantly, these frames are much faster to render. When generating millions of frames, this speedup let us test much faster. All of this culminated in Babble v2.1.0RC4, our current production face tracking model.